WebScrapBook geliştiren: Danny Lin
Capture web pages to local device or backend server for future retrieval, organization, annotation, and edit.
6.644 kullanıcı6.644 kullanıcı
Uzantı meta verileri
Ekran görüntüleri


Bu uzantı hakkında
WebScrapBook is a browser extension that captures the web page faithfully with various archive formats and customizable configurations, for future retrieval, organization, annotation, and editing. This project inherits from legacy Firefox add-on ScrapBook X.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
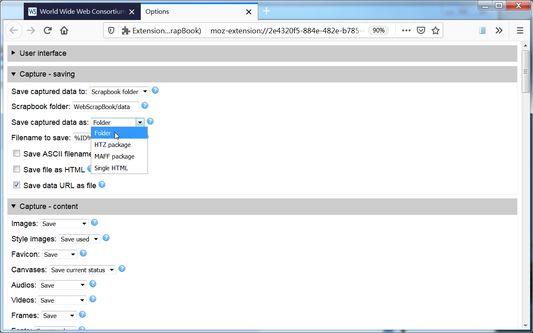
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
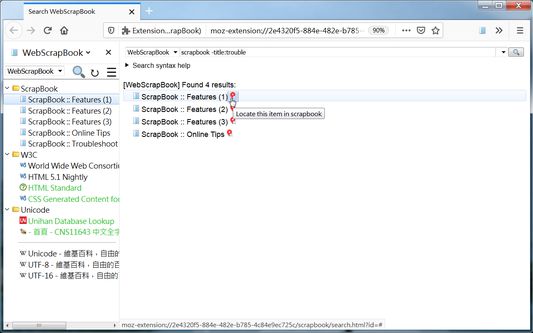
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook.
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, using PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki.
* For better discussion, please report an issue to the source repository.
144 inceleyiciden 4 puan aldı
İzinler ve veriler
Gerekli izinler:
- Dosya indirme, tarayıcının indirme geçmişini okuma ve değiştirme
- Tarayıcı sekmelerine erişme
- Gezinti sırasında tarayıcı etkinliğine erişme
- Tüm web sitelerine ait verilerinize erişme
İsteğe bağlı izinler:
- Konumunuza erişme
Daha fazla bilgi
- Eklenti bağlantıları
- Sürüm
- 2.25.1
- Boyut
- 507,82 KB
- Son güncelleme
- 2 ay önce (10 May 2026)
- İlgili kategoriler
- Lisans
- Mozilla Kamu Lisansı 2.0
- Sürüm geçmişi
- Etiketler
- Koleksiyona ekle
Bu uzantının geliştiricisi, küçük bir bağışta bulunarak gelişimin devamı için katkıda bulunmanızı rica ediyor.